DevOps: Hybrid Clusters with On-Premise Bare-Metal K8s and AWS EKS

For high availability and cost optimization, a case study of a hybrid cluster that combines on-premise and public cloud. Photo by Photobank Kiev on Unsplash
이 문서에 대한 한국어 버전은 이 링크를 참고해주세요.
1. Overview
My team and I built a hybrid Kubernetes cluster that combines on-premise and public cloud resources. This architecture helps us overcome the limitations of on-premise resources and optimize the cost of public cloud usage.
Our application consists of two parts: a web application and machine learning (ML) pipelines. The web application is hosted on the public cloud, while the ML workload runs on the on-premise GPU servers. The hybrid cluster architecture provides the following benefits:
- Reliability: Hosting the web applications and databases on the public cloud helps us achieve high availability and reliability 24/7.
- Cost Optimization: By using the on-premise GPU servers for ML workloads, we reduced the cost of public cloud resources by over 50%.
- Scalability: When the on-premise cluster runs out of resources, we can easily scale out to the public cloud. Even if the on-premise cluster is down, the public cloud extends backup nodes to ensure high availability for ML workloads.
The following diagram shows the architecture of the hybrid cluster:
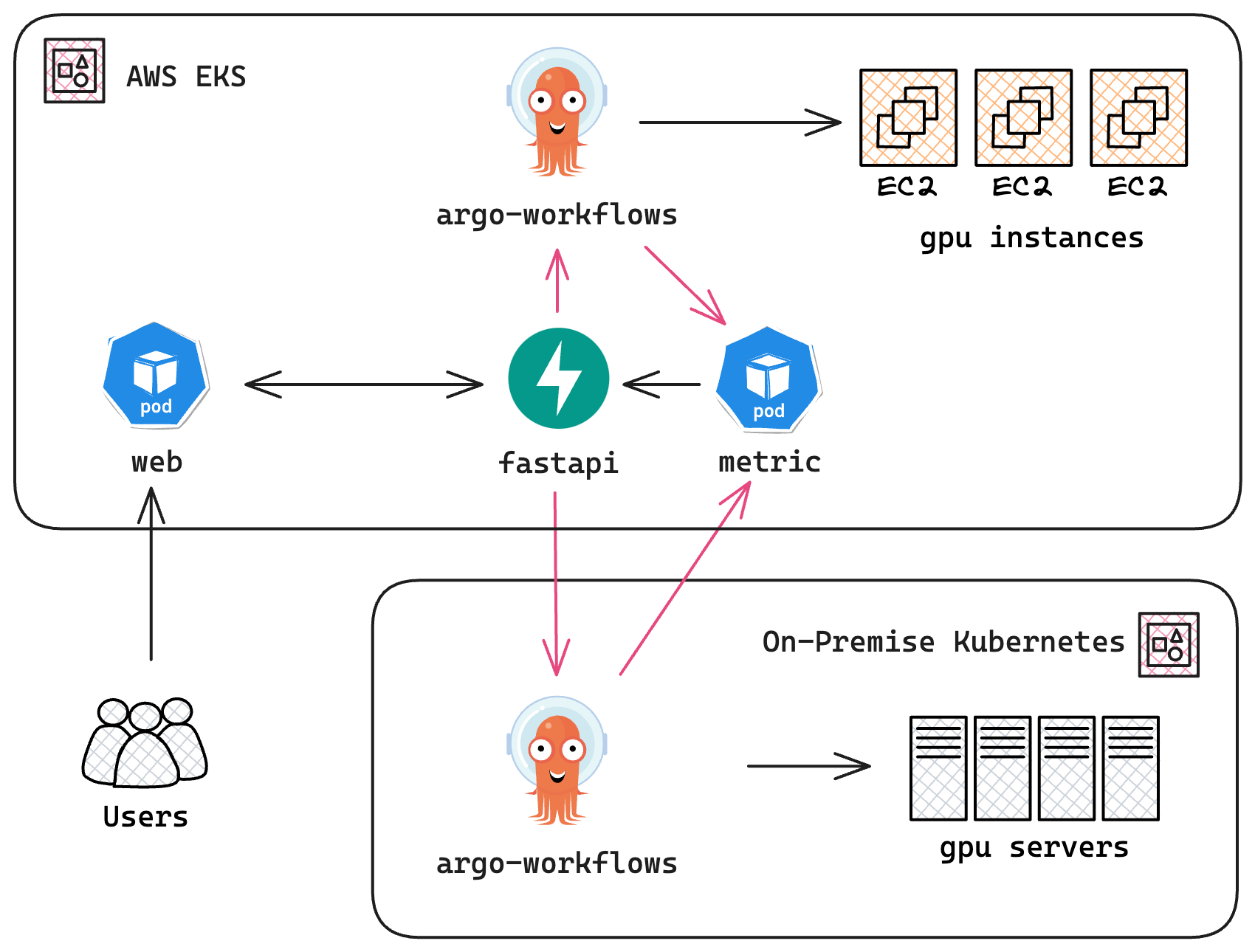
Architecture Diagram of the Hybrid Cluster for DevOps; Users interact with a web application hosted on a public cloud platform like AWS EKS, while the ML pipelines execute on an on-premise cluster. We utilize Argo Workflows as the workflow controller. A metric collector monitors the liveness and availability of the on-premise cluster and triggers scale-out of backup pipelines in the public cloud when necessary. The metrics server is implemented using FastAPI.
2. Problem Statement
Initially, we deployed a public AWS EKS cluster to support our web application and ML pipeline. However, running ML workloads on the public cloud proved to be cost-ineffective due to the high expense of GPU instances (e.g., g4dn) on AWS EC2, resulting in unacceptable monthly costs amounting to thousands of dollars.
To mitigate these costs, we transitioned to on-premise clusters equipped with GPU servers for our ML pipelines. To facilitate communication between the public cloud and our on-premise clusters, we needed to expose endpoints on the on-premise cluster.
A metric collector in the public cloud was set up to monitor the liveness and availability of the on-premise cluster. In the event of the on-premise cluster going down or lagging, the metric collector would automatically scale out public cloud resources to maintain high availability of the ML pipelines.
3. Methods
To achieve the architecture described above, we implemented the following steps:
3.1. Public Cluster: AWS EKS
We deployed a public AWS EKS cluster to host our web application and database. The EKS cluster deployed the following components:
- Web Application: A web application that serves as the front-end and CMS for users.
- Database: PostgreSQL and MySQL databases that store user data and application logs.
- Metric Collector: A metric collector that monitors the liveness and pipeline availability of the on-premise and public clusters.
- Backup ML Pipelines: Backup pipelines that are automatically scaled out in the event the on-premise cluster is not available.
3.2. On-Premise Cluster: Bare-Metal Kubernetes
We deployed on-premise bare-metal Kubernetes clusters with GPU servers. The on-premise cluster deployed the following components:
- ML Pipelines: Machine learning pipelines that process data and train models. The pipelines run on GPU servers to accelerate the training process. We used Argo Workflows as a pipeline controller.
- Metrics Server: A metrics server that exposes the liveness and availability of the on-premise cluster to the public cloud. We used FastAPI and Prometheus SDK to implement the metrics server.
3.3. Scheduling ML Pipelines
If the on-premise cluster is down or lagging, the metric collector in the public cloud will automatically scale out the backup ML pipelines to ensure high availability of the ML workloads. The metric collector will also scale in the backup pipelines when the on-premise cluster is back online.
4. Summary
This is a case study of a loosely-coupled hybrid cluster that combines on-premise and public cloud resources. The architecture provides high availability, cost optimization, and scalability for our application.
We reduced the cost of public cloud resources by over 50% by running ML workloads on on-premise GPU servers. The public cloud provides high availability and reliability for our web application and database.
The metric collector alerts us when the on-premise cluster is unavailable and automatically scales out the backup pipelines to ensure high availability of the ML workloads. This allows us to adjust the scale of the public cloud resources based on the availability of the on-premise cluster.
5. Future Works
Recently, we noticed that there are use cases utilizing AWS EKS Anywhere to combine on-premise and public nodes in a single EKS cluster. We are planning to proof the concept and migrate our on-premise cluster to EKS Anywhere to simplify the management of the hybrid cluster.
6. Used Skills
Highlighted skills used in this project: