MLOps: On-Premise MLOps with the Latest Open Source Projects

To reduce underutilized GPU time, a case study of an on-premise cluster that provides MLOps services with Kubeflow, Argo Workflows, and more.
Photo by Maxim Hopman on Unsplash
1. Overview
Our team has built an on-premise MLOps cluster utilizing the latest open-source projects, including Kubeflow, JupyterHub, and Data Pipelines. With limited GPU resources, the architecture is designed to reduce underutilized GPU time and optimize the cost of running ML workloads. Additionally, a single training job can be accelerated by utilizing multiple GPUs in parallel, allowing it to leverage all GPUs in the cluster beyond the resources of a single GPU server.
With on-premise resources, our MLOps cluster provides the following advantages:
- Resource Utilization: The cluster can efficiently utilize all available GPU resources in the cluster, reducing underutilized GPU time. 24/7 GPU usage has increased GPU utilization by three times againt the previous environment.
- AutoML: The cluster supports AutoML workflows, enabling automated model selection, hyperparameter tuning. The cluster can run more than 800 experiments for two weeks. The results were used for commercialization.
- Parallel Training: A single training job can be accelerated by utilizing multiple GPUs in parallel, allowing it to leverage all GPUs in the cluster.
- Remote Notebooks: The cluster provides researchers with on-demand Jupyter notebooks to distribute resources for ML research. Researchers can easily access the cluster and run experiments without worrying about resource constraints.
The following diagram shows the architecture of the on-premise cluster for MLOps:
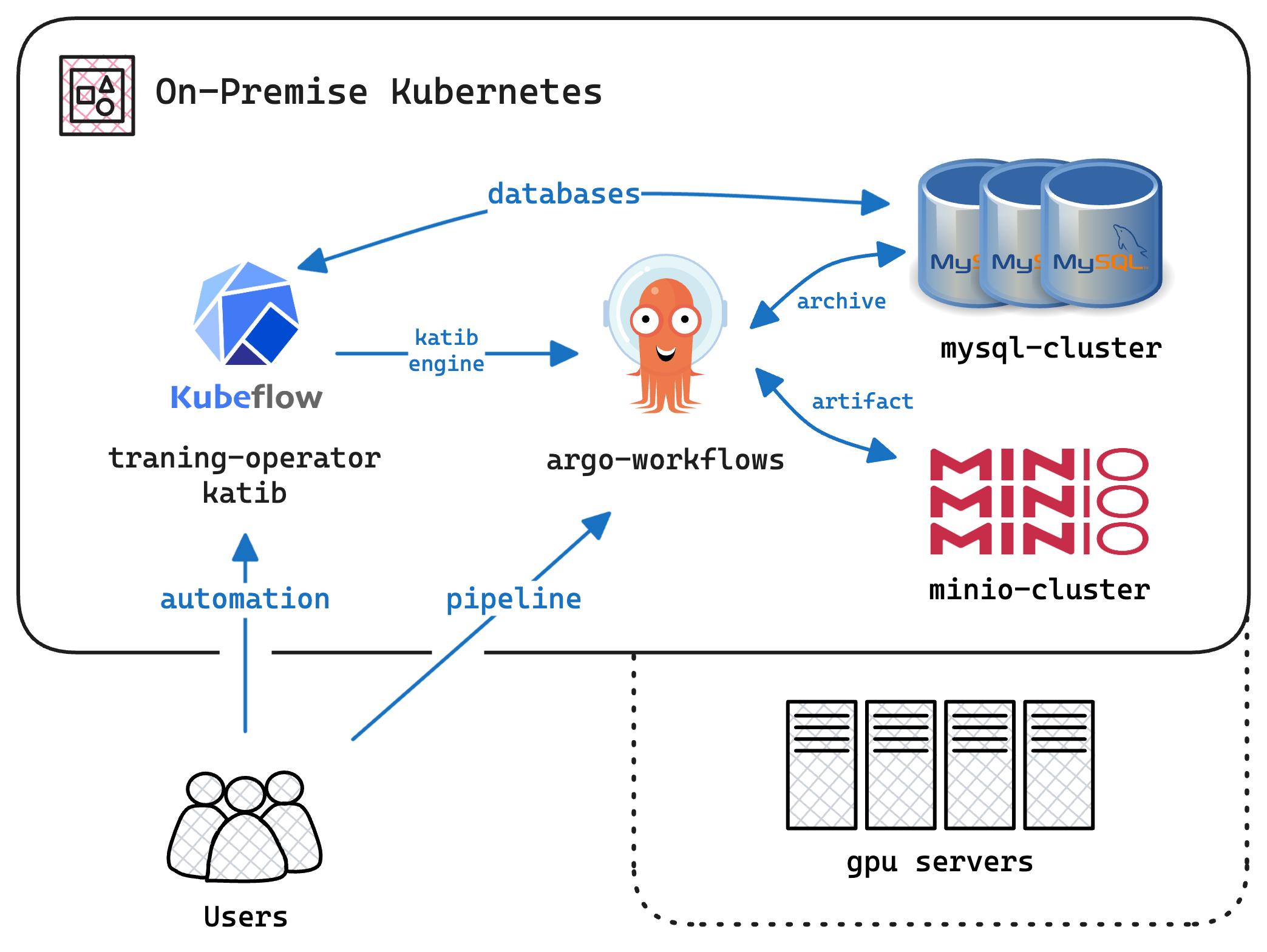
Architecture Diagram of the On-Premise Kubernetes Setup for MLOps; Users interact with Kubeflow for managing and automating machine learning workflows. Kubeflow/Katib utilizes the Argo Workflows as a workflow engine for hyperparameter tuning and Kubeflow/Training Operator for managing training jobs. Argo Workflows orchestrates these machine learning pipelines. The MySQL cluster stores workflow metadata and results, while the Minio cluster handles artifact storage. The cluter contains GPU servers providing computational power for training models. This setup ensures efficient data handling and workflow management in an on-premise Kubernetes environment.
2. Problem Statement
AI researchers in our organization were facing challenges with limited GPU resources. Each researcher was allocated a single GPU server, which led to underutilized GPU time when the server was idle and insufficient resources for large-scale experiments.
To address these challenges, we proposed integrating the GPU servers into the cluster and implementing an MLOps platform based on open-source projects. Our goals were followings:
- Resource Sharing: Allow researchers to share GPU resources in the cluster and leverage all available GPUs for their experiments.
- User-Friendly Environments: Provide researchers with an easy-to-use environment for developing and running ML experiments.
- AutoML Support: Implement AutoML workflows to automate model selection, hyperparameter tuning, and model evaluation.
- Parallel Training: Enable parallel training of models by utilizing multiple GPUs in the cluster.
- Remote Notebooks: Provide researchers with on-demand Jupyter notebooks to distribute resources for ML research.
The project started with a Proof of Concept (PoC) to demonstrate the benefits of the MLOps platform and its impact on AI research.
3. Methods
To achieve the architecture described above, we implemented the following steps:
3.1. Setup On-Premise Cluster
We already had an on-premise cluster with GPU servers. We integrated the GPU servers into the cluster and configured the cluster to support MLOps workflows. The cluster deployed the following core components:
- Argo Workflows: General purpose workflow controller for Kubernetes to run ML pipelines. Using Argo Workflows, we could provide researchers with a flexible and scalable workflow system without extra setup.
- GPU Operator: Operator to manage GPU resources in the cluster and enable researchers to utilize all available GPUs for their experiments.
- Kubeflow: Machine learning toolkit for Kubernetes that provides a platform for running, training, and deploying ML models. We used Kubeflow to manage trains and experiments.
We chose these open source project to build license-free environments and easily customizable environments for researchers and devops engineers.
3.2. Implement Data Pipelines with Argo Workflows
No, Kubeflow this time: Kubeflow is a machine learning toolkit for Kubernetes. It provides a platform for running, training, and deploying ML models. We used Kubeflow to manage trains and experiments. But, in this case, we used Argo Workflows to manage data pipelines. The reason is that Argo Workflows is more flexible and easier to use for data pipelines. There are some facts of Kubeflow for data pipelines:
Instant Static Graph: Kubeflow Pipeline shows a built-in static graph of the pipeline. It provides a visual representation of the pipeline so that researcher can easily understand how the pipeline works.
Requiring Pre-Build: Kubeflow requires pre-build data pipelines, which can be time-consuming and inflexible. Jobs of Kubeflow Pipeline require pre-build images for training and inference. So it is not easy to modify the pipeline rapidly. CI/CD pipelines might be helpful, but it still requires extra effort. This fact was a key disadvantage deciding to use Argo Workflows.
Again, Argo Workflows: Argo Workflows is general purpose workflow controller for cloud native environments. With GPU Operator, the workflow can provide any graph structure of data pipelines. Generally, Argo Workflows are defined in YAML files, but we used Hera, an Argo Workflows SDK that allows us to define workflows in Python scripts. This approach made it easier to create and modify workflows for ML researchers. There are some facts of Argo Workflows for data pipelines:
No Pre-Build: Argo Workflows does not require pre-build images for data pipelines. Researchers can define the pipeline in Python scripts and run it directly. This flexibility allows researchers to modify the pipeline easily and run experiments quickly.
In training stage, you can use pre-built images and add some script to traing models. Or you can use scratch CUDA images and setup the environment in the workflow with Hera SDK. In inference stage, you can choose same way as training stage.
No built-in graph. Everything are DIY: Argo Workflows does not provide a built-in graph of the pipeline. Researchers need to define the graph structure in the Python script. This flexibility allows researchers to create custom pipelines tailored to their specific needs. This can be both pro and con. If you need a visualized graph, you can use tools like Grafana or TensorBoard to monitor the pipeline.
Simply, if you have Argo Workflows in your cluster, you already have a data pipeline system via Argo Workflows and Hera SDK.
3.3. Setup Katib AutoML in Kubeflow
Katib AutoML provides hyperparameter tuning for ML models and visualized parallel coordinates graph for researchers. We used Katib to automate the process of tuning hyperparameters and selecting the best model for the given dataset. Katib supports external engines like Argo Workflows, so we integrated Katib with Argo Workflows to manage the AutoML process.
The core function of Katib is continuous hyperparameter tuning. Researchers can define the search space of hyperparameters and the objective metric to optimize. Katib will run multiple experiments in parallel, tuning the hyperparameters based on the objective metric. Researchers can monitor the progress of the experiments and select the best model based on the results. And GPU resources can be used 24/7 for AutoML experiments. We ran 800+ experiments for two weeks and used the results for commercialization.
3.4. Setup Training Operator in Kubeflow
We chose Kubeflow Training Operator to manage distributed training environments. The Training Operator provides a high-level abstraction for training jobs, allowing researchers to utilize all available GPUs in the cluster for parallel training. But in v1.6, the version we used, the Training Operator does not support external engine like Argo Workflows. So we used pure Kubeflow Training Operator to manage distributed training environments.
The Training Operator allows researchers to define training jobs with custom resources, such as the number of GPUs, memory, and CPU cores. We configured a certain training job with 8 GPUs from 2 GPU servers, and the job was distributed across the GPUs for parallel training. This approach allowed researchers to accelerate the training process and utilize all available GPU resources in the cluster without setting up additional infrastructure.
3.5. Deploy JupyterHub for Researchers
We chose JupyterLab in the first place, but we decided to use JupyterHub for researchers to access the cluster. JupyterHub provides current status of the cluster and researchers can figure how many resources are available in the cluster.
We setup the pre-built notebook images for researchers to use. The images contain the necessary libraries and tools for ML research, such as TensorFlow, PyTorch, and scikit-learn. Researchers can easily access the data lakes with provisioned NFS storage and run experiments without worrying about resource constraints.
4. Summary
In this project, we built an on-premise MLOps cluster with the latest open-source projects, including Kubeflow, Argo Workflows, and JupyterHub. The cluster provides researchers with a flexible and scalable environment for developing and running ML experiments. With limited GPU resources, the cluster can efficiently utilize all available GPUs in the cluster, reducing underutilized GPU time and optimizing the cost of running ML workloads.
5. Future Works
In the future, we are planning to enhnace user experience. ML researchers asked two convinent functions:
- Monitoring: Researchers want to monitor the progress of their experiments and visualize the results in real-time. We are planning to integrate Grafana to provide monitoring dashboards for researchers.
- SSH Access for Notebooks: Researchers also want to access Jupiter notebooks via SSH. The custom spawner for JupyterHub will be implemented to provide SSH access for researchers. or we will chatbot generates stack of notebooks directly.
6. Used Skills
Highlighted skills used in this project: